การจําแนกข้อความ SMS ภาษาไทย จากมิจฉาชีพ ด้วย Machine Learning
Article Sidebar
Main Article Content
บทคัดย่อ
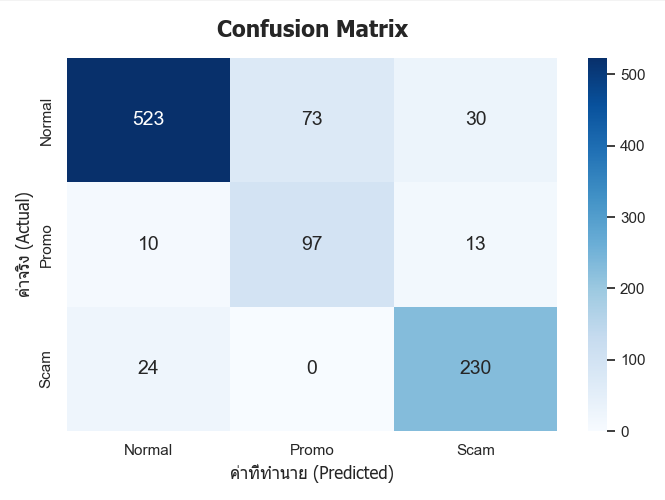
การวิจัยครั้งนี้มีวัตถุประสงค์ 1) เพื่อการจำแนกข้อความ SMS ภาษาไทยจากมิจฉาชีพด้วย Machine Learning 2) ศึกษาการใช้อัลกอริทึม PyThaiNLP ร่วมกับเทคนิค TF-IDF ในการสกัดคุณลักษณะข้อความ และประยุกต์ใช้เทคนิค SMOTE เพื่อแก้ไขปัญหาความไม่สมดุลของข้อมูล ก่อนนำไปฝึกด้วยอัลกอริทึม Naïve Bayes และ 3) ศึกษาผลของแบบจำลองในการจำแนกข้อความ SMS ภาษาไทยออกเป็น 3 กลุ่ม ได้แก่ ข้อความปกติ ข้อความมิจฉาชีพ และข้อความส่งเสริมการขาย โดยใช้ข้อมูลจำนวน 5,000 รายการ ผลการทดลองด้วยอัลกอริทึม Naïve Bayes พบว่า กลุ่มข้อความปกติมีค่า Precision (ความแม่นยำ) 0.94 Recall (ความระลึก) 0.84 และ F1-Score (ค่าความถ่วงดุล) 0.88 กลุ่มข้อความส่งเสริมการขายมีค่า Precision 0.57 Recall 0.81 และ F1-Score 0.67 และกลุ่มข้อความมิจฉาชีพมีค่า Precision 0.84 Recall 0.91 และ F1-Score 0.87 ซึ่งแสดงให้เห็นถึงประสิทธิภาพที่ดีของแบบจำลอง โดยเฉพาะในการตรวจจับข้อความมิจฉาชีพ นอกจากนี้ การประยุกต์ใช้เทคนิค SMOTE ช่วยเพิ่มประสิทธิภาพของแบบจำลอง โดยให้ค่าความถูกต้อง (Accuracy) สูงสุดร้อยละ 85.00 พร้อมทั้งให้ค่าความแม่นยำ ความระลึก และค่าความถ่วงดุลอยู่ในระดับดีเยี่ยม สรุปได้ว่าแนวทางดังกล่าวสามารถนำไปใช้ในการตรวจจับข้อความ SMS มิจฉาชีพได้อย่างมีประสิทธิภาพ
Article Details

อนุญาตภายใต้เงื่อนไข Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
เอกสารอ้างอิง
ธ. ไทยพาณิชย์, “คลิกเดียวชีวิตเปลี่ยน! วิธีรับมือ ‘ลิงก์แปลกปลอม’ และ ‘ข้อความหลอกลวง,’”, [ออนไลน์]. https://www.scb.co.th/th/personal-banking/fraud-fighter/update-fraud/sms-one-click. (เข้าถึงเมื่อ: 9 เมษายน 2569).
W. Phatthiyaphaibun et al., "PyThaiNLP: Thai Natural Language Processing in Python," in Proc. 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023), 2023, pp. 25–36.
ศวิตา ทองขุนวงศ์ และ ภัคพล สวัสกมล, "การเปรียบเทียบประสิทธิภาพของตัวแบบการเรียนรู้ของเครื่องสำหรับการจำแนกผู้ป่วยโรคมะเร็งปอด," วารสารวิจัย มทร. กรุงเทพ, ปีที่ 18, ฉบับที่ 1, หน้า 33–42, มกราคม–มิถุนายน 2567.
N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, "SMOTE: Synthetic minority over-sampling technique," J. Artif. Intell. Res., vol. 16, pp. 321–357, Jun. 2002.
นันทวัฒน์ หล้าซิว, "กรอบพัฒนาวิธีการจำแนกประเภทข้อความสนทนาด้วยเทคนิคการเรียนรู้เชิงลึกร่วมกับเทคนิคการเพิ่มข้อมูล," วิทยานิพนธ์ วท.ม. (วิทยาการคอมพิวเตอร์), มหาวิทยาลัยธรรมศาสตร์, กรุงเทพฯ, 2566.
H. C. Wu, R. W. P. Luk, K. F. Wong, and K. L. Kwok, "Interpreting TF-IDF term weights as making relevance decisions," ACM Trans. Inf. Syst., vol. 26, no. 3, pp. 1–37, Jun. 2008.
องอาจ อุ่นอนันต์ และ พยุง มีสัจ, "การจำแนกความน่าเชื่อถือของเว็บไซต์แหล่งข่าวภาษาไทยโดยใช้เทคนิคการทำเหมืองข้อมูล," วารสารวิชาการมหาวิทยาลัยอีสเทิร์นเอเชีย ฉบับวิทยาศาสตร์และเทคโนโลยี, ปีที่ 14, ฉบับที่ 2, หน้า 101–116, พฤษภาคม–สิงหาคม 2563.
วสันต์ เจริญทองตระกูล, "พฤติกรรมการรับส่งข้อความสั้น (SMS) ทางโทรศัพท์เคลื่อนที่ของนักเรียน นิสิต นักศึกษา ในกรุงเทพมหานคร," วิทยานิพนธ์ ว.ม. (สื่อสารมวลชน), มหาวิทยาลัยธรรมศาสตร์, กรุงเทพฯ, 2546.
สุปราณี วงษ์แสงจันทร์, ประภาพร กุลลิ้มรัตน์ชัย และ พิมล จงวรนนท์, "การรับมือกับกลโกงในโลกไซเบอร์," วารสารวิชาการมหาวิทยาลัยอีสเทิร์นเอเชีย ฉบับวิทยาศาสตร์และเทคโนโลยี, ปีที่ 19, ฉบับที่ 2, หน้า 14–26, พฤษภาคม–สิงหาคม 2568.
สิริลักข์ เมืองนิล, ศุภกร ปุญญฤทธิ์ และ สุณีย์ กัลยะจิตร,"การป้องกันการตกเป็นเหยื่อแก๊งคอลเซ็นเตอร์," วารสารกระบวนการยุติธรรม, ปีที่ 18, ฉบับที่ 3, หน้า 1–22, พฤษภาคม–สิงหาคม 2568.
ชวัลวิทย์ โสภาศิริทรัพย์, สุณีย์ กัลยะจิตร และ พรชุลี นาคพงษ์, "แนวทางป้องกันการตกเป็นเหยื่อหลอกรักออนไลน์ (Romance Scam)," วารสารกระบวนการยุติธรรม, ปีที่ 17, ฉบับที่ 3, หน้า 1–16, กันยายน–ธันวาคม 2567.
